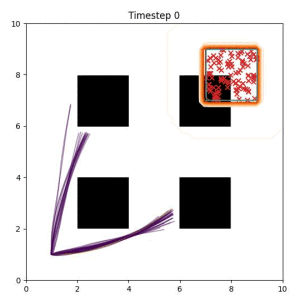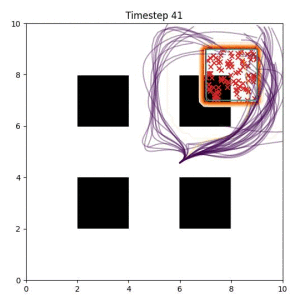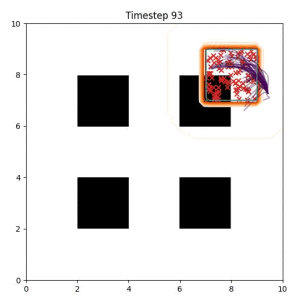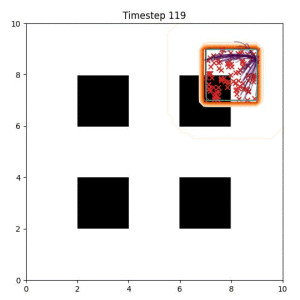
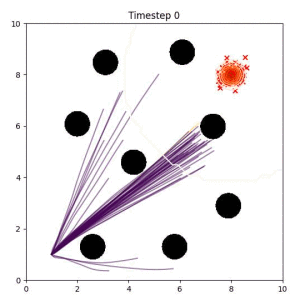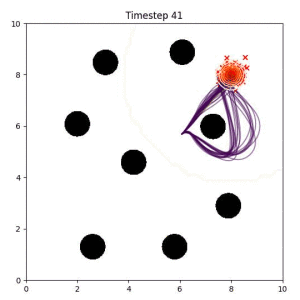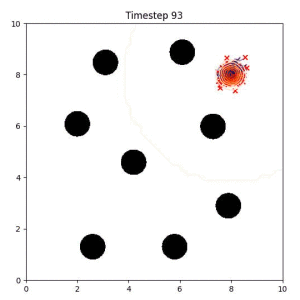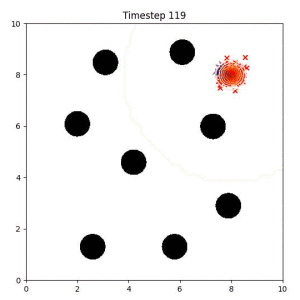
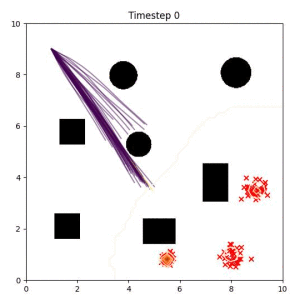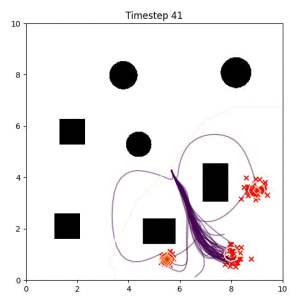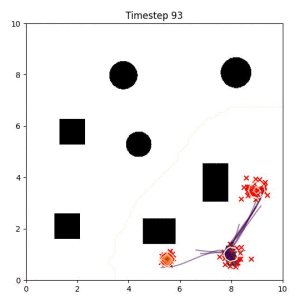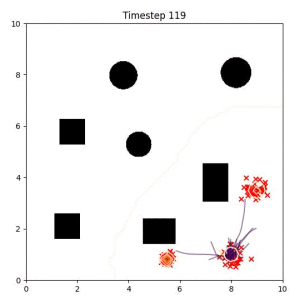
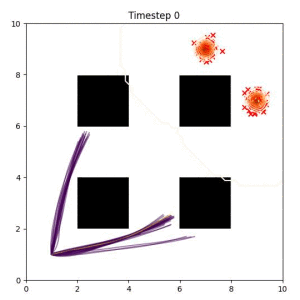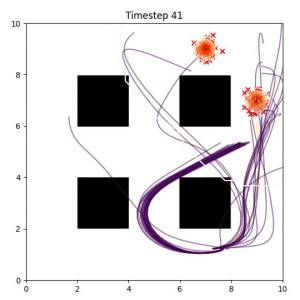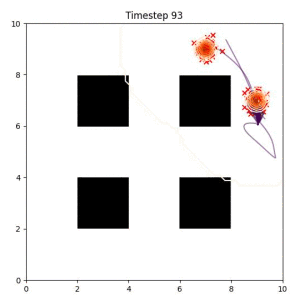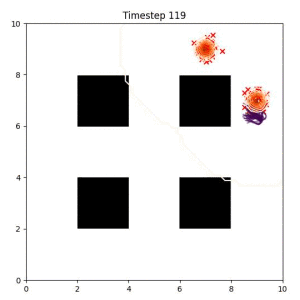
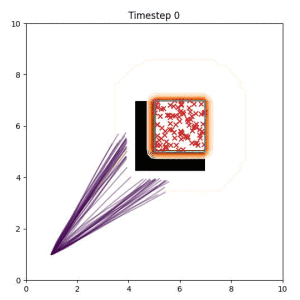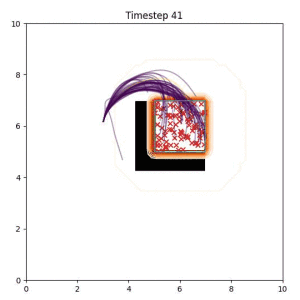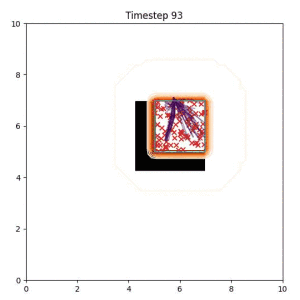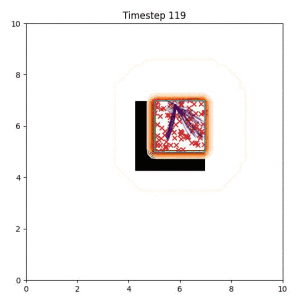
Many robotic tasks can have multiple and diverse solutions and, as such, are naturally expressed as goal sets. Examples include navigating to a room, finding a feasible placement location for an object, or opening a drawer enough to reach inside.
Using a goal set as a planning objective requires that a model for the objective be explicitly given by the user. However, some goals are intractable to model, leading to uncertainty over the goal (e.g. stable grasping of an object).
In this work, we propose a technique for planning directly to a set of sampled goal configurations. We formulate a planning as inference problem with a novel goal likelihood evaluated against the goal samples.
To handle the intractable goal likelihood, we employ generalized Bayesian inference to approximate the trajectory distribution.
The result is a fully differentiable cost which generalizes across a diverse range of goal set objectives for which samples can be obtained.
We show that by considering all goal samples throughout the planning process, our method reliably finds plans for manipulation and navigation problems where heuristic approaches fail.
The goal set planner considers a set of goal samples as the planning objective. Our planner is better than heuristic baselines at maintaining modes of the trajectory distribution, leading to a higher likelihood that at least one feasible path to the goal region will be found.
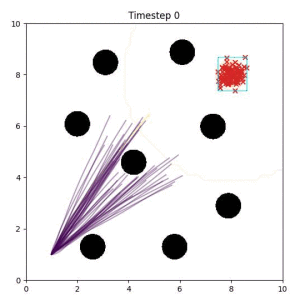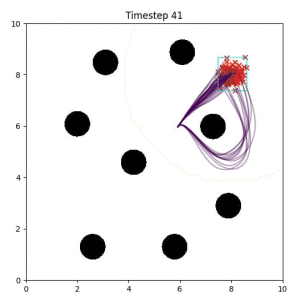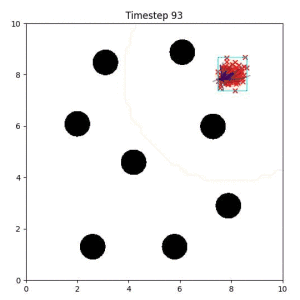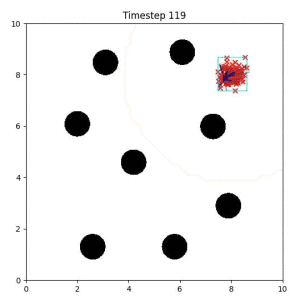
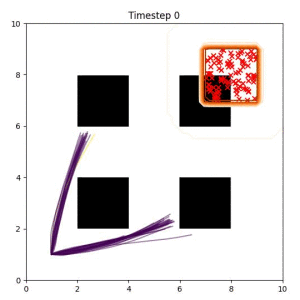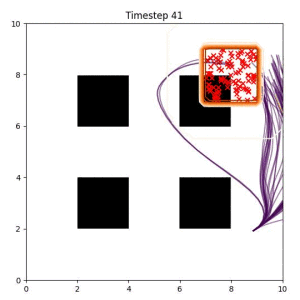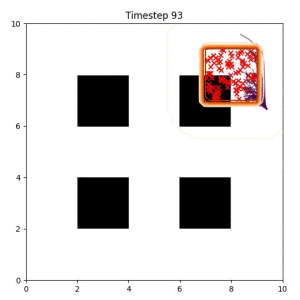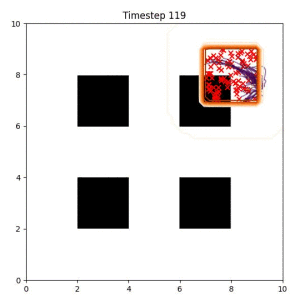
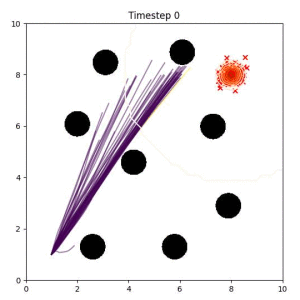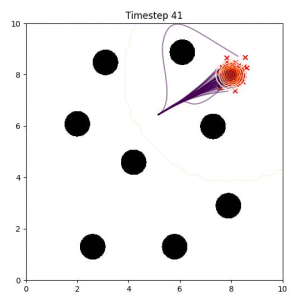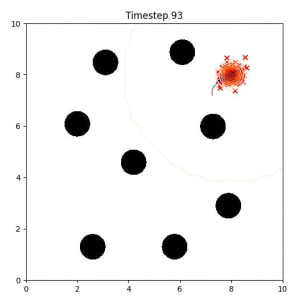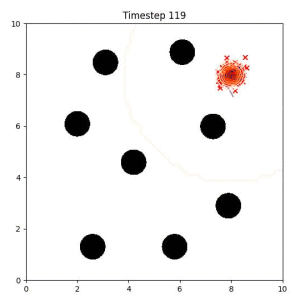
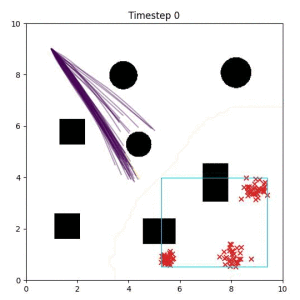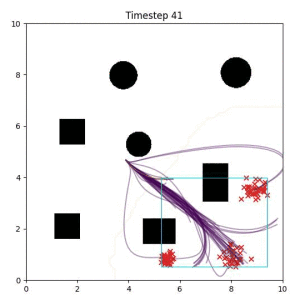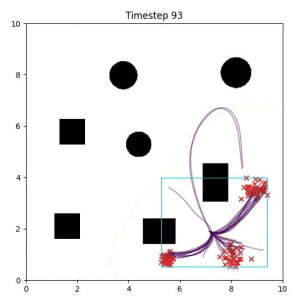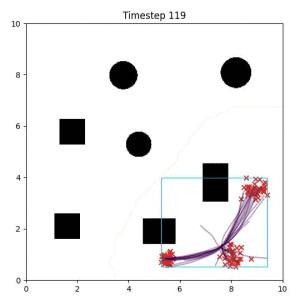
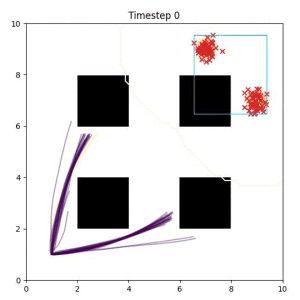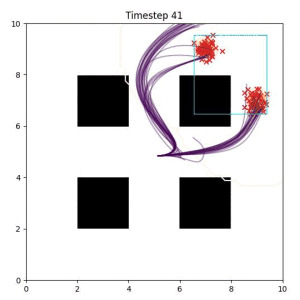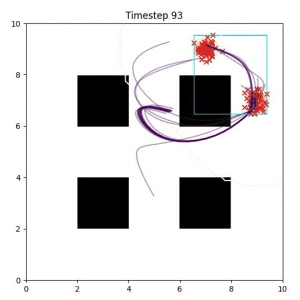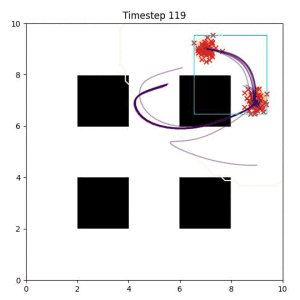
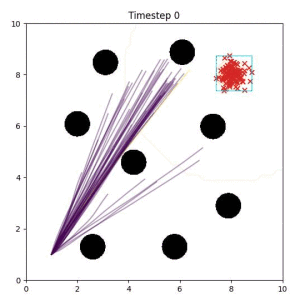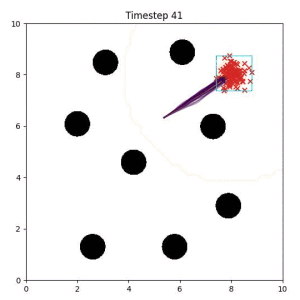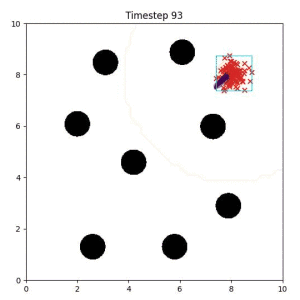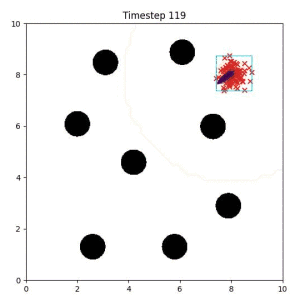
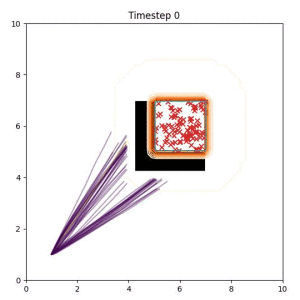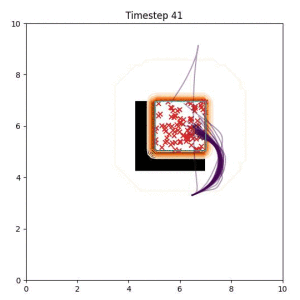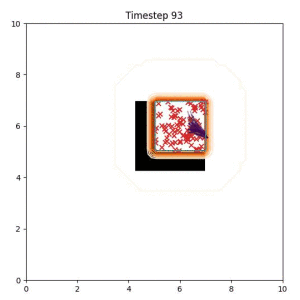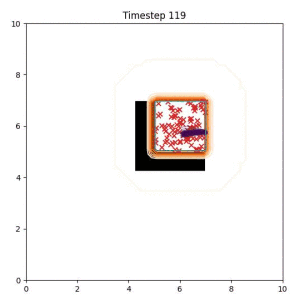
In the examples below, the purple lines represent the trajectory distribution at each timestep. The red X's represent goal samples, and the orange contours represent the true user-defined goal distribution. Note that only the "Cross Entropy" oracle baseline has access to the true underlying distribution.
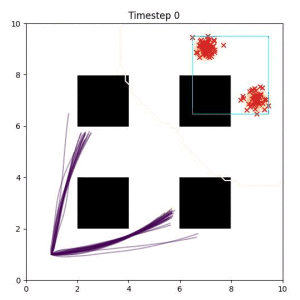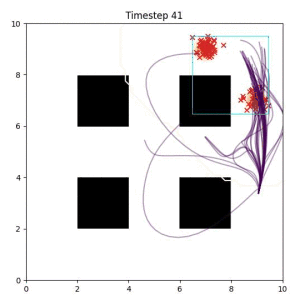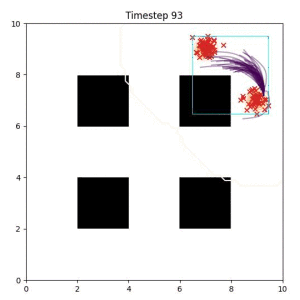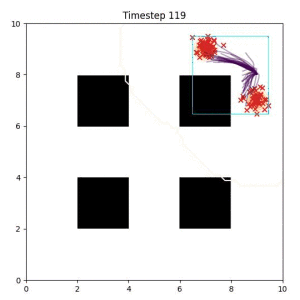
Closest Point (Baseline):
Selecting one single goal from the set of goal points can lead to a goal that is difficult or impossible to reach. (The selected goal is a red "x" in the bottom left corner of the box.)
Cross Entropy (Oracle Baseline):
Using the true goal distribution density as a likelihood can lead to local minima in the trajectory estimate. Note that in some more complicated examples, the true distribution is not always available.
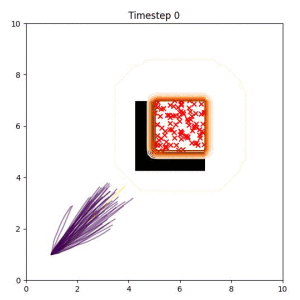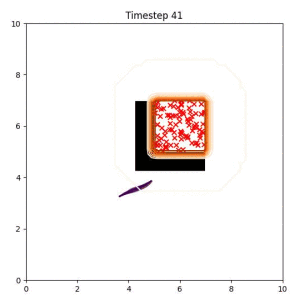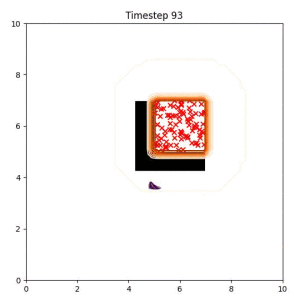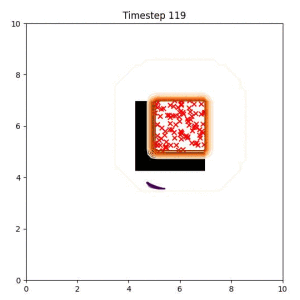
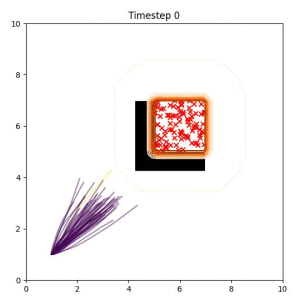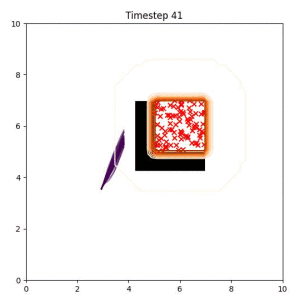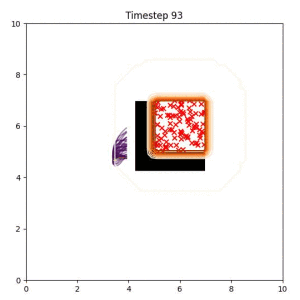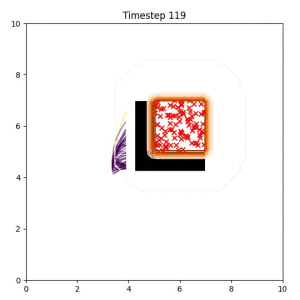
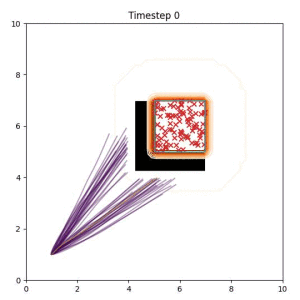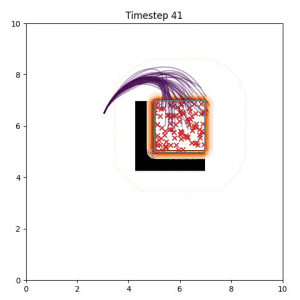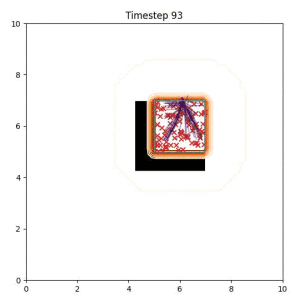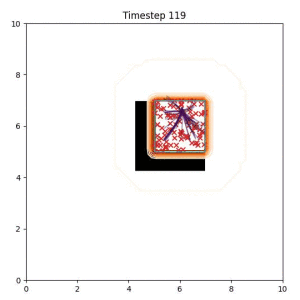
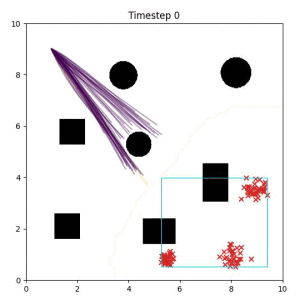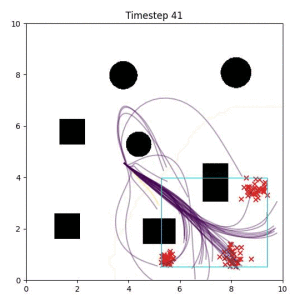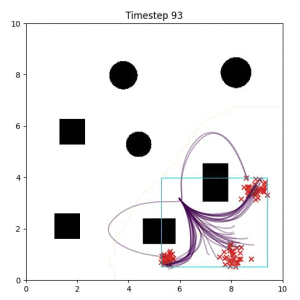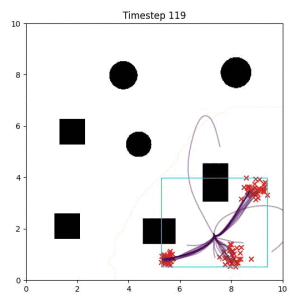
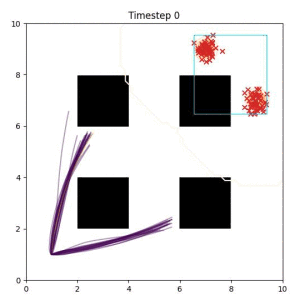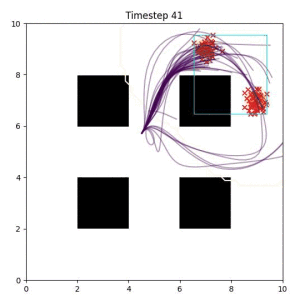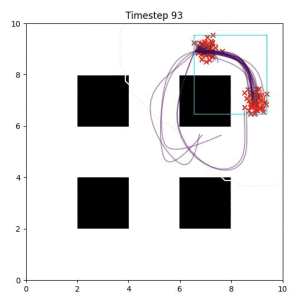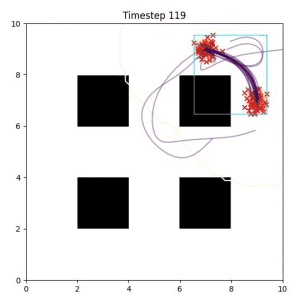
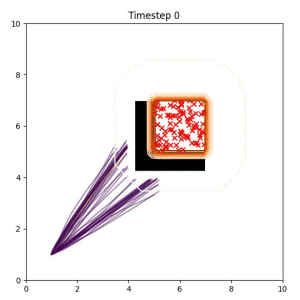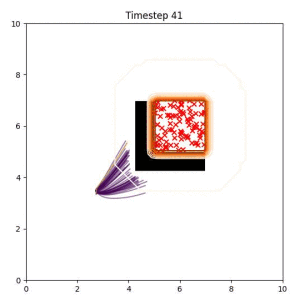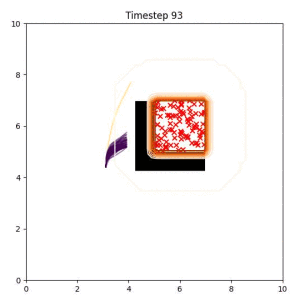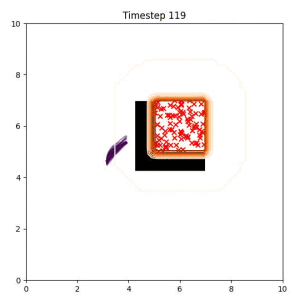
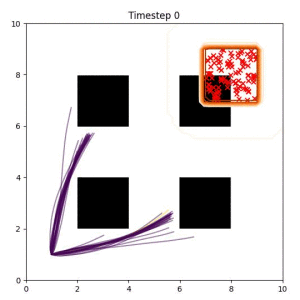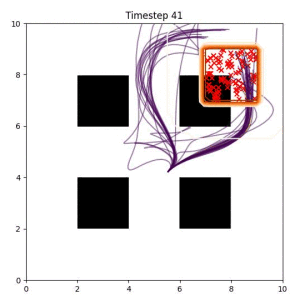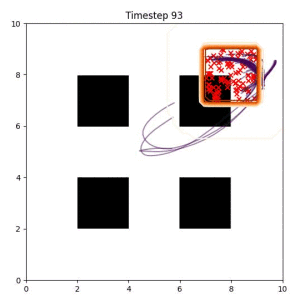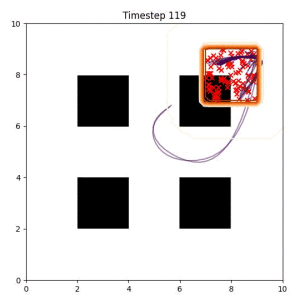
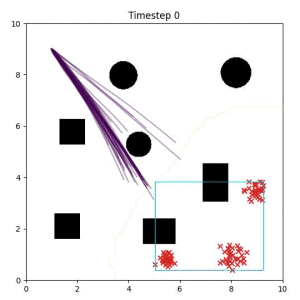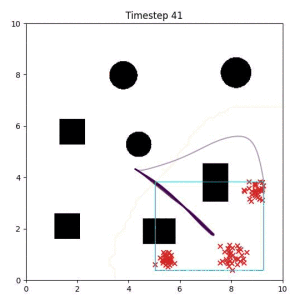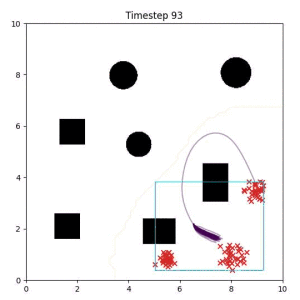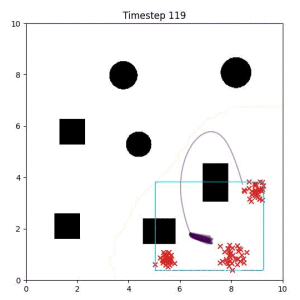
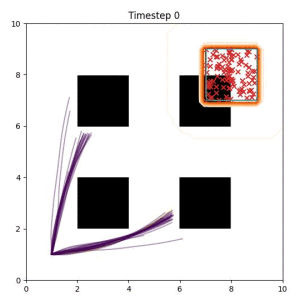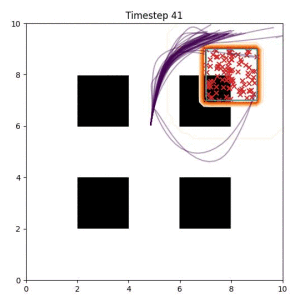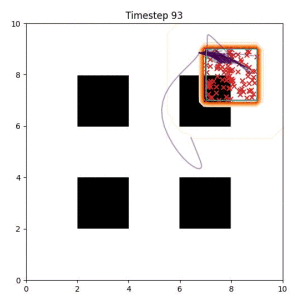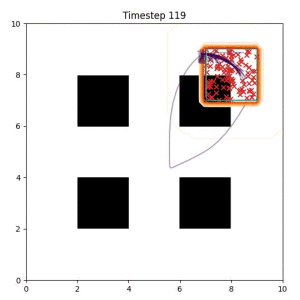
Goal Set Planner (Ours):
The nature of the goal set planner encourages the terminal points in the trajectory to match the goal samples. This increases the chance that a successful path to the goal region is found.
Terminal Losses
Multiple terminal losses can be used within the goal set planner formulation. We implement and analyse four different options, all of which consists of two-sample tests where both the trajectories and goal are represented implicitly in terms of samples. All losses examined are fully differentiable with respect to the trajectory.
A two-sample approximation of the KL divergence, where the density ratio is approximated by training a classifier on the sample points (Menon and Ong, ICML, 2016).
The energy statistic defined by Székely and Rizzo (JSPI 2013).
Robotic Grasping
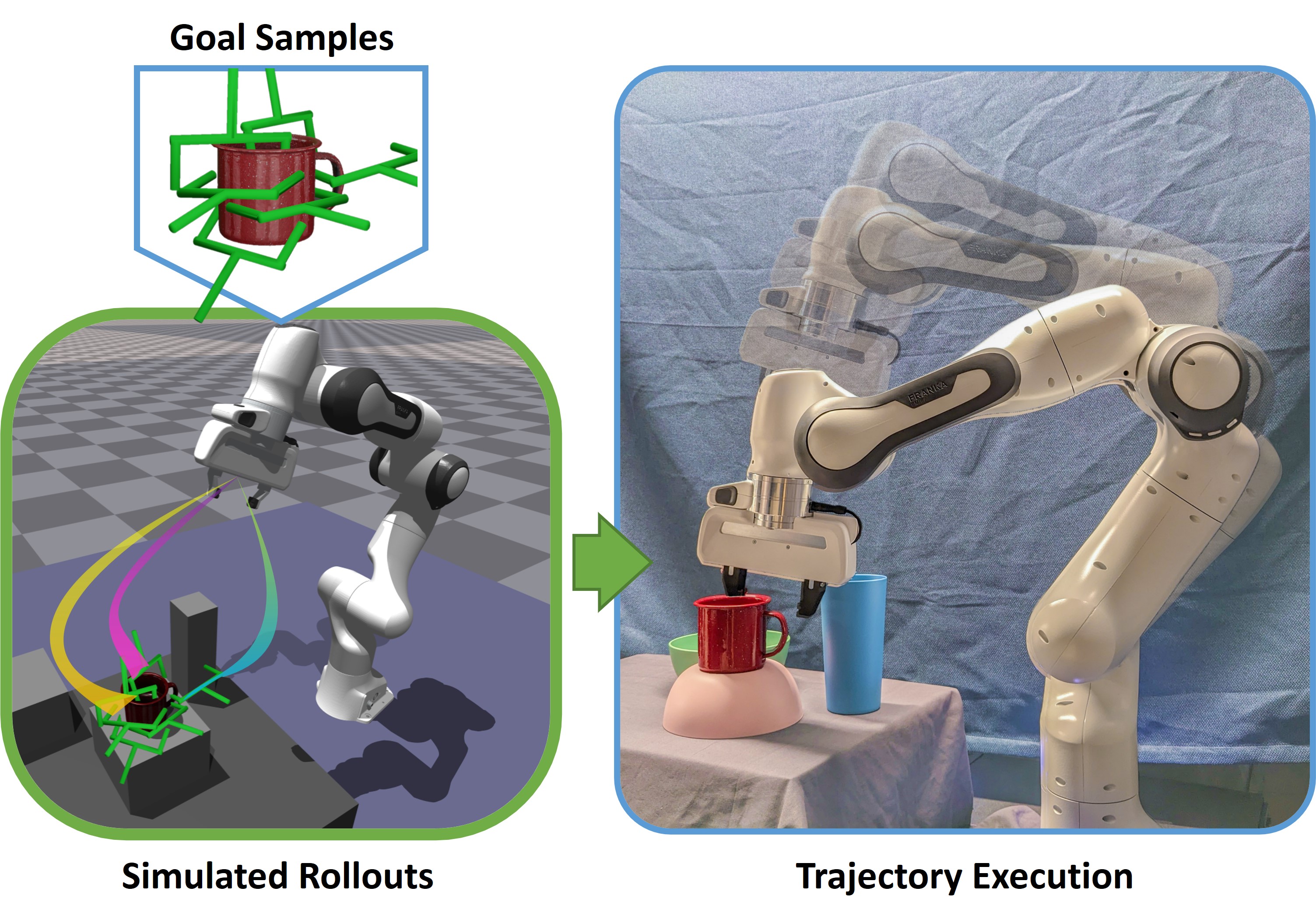
Stable grasping is an example of a task for which the goal distribution is difficult to describe explicitly. Many popular approaches instead use data-driven techniques, in which grasp candidates are evaluated through simulation. We use valid goal samples from the Acronym dataset as a goal set and perform trajectory planning to the samples directly. In practice, we plan to offset pre-grasp poses, then switch to a point goal solver for the grasping action.
Goal Set Planning for Robotic Plan-to-Grasp (Ours)
Our planner considers a set of provided valid grasp points (green) as a goal. In this example, only a subset of the grasps are reachable. The goal set planner seeks to find a path to the goal samples while jointly optimizing for cost and collision avoidance. As such, the planner determines good goal regions on the fly.
Single Point Planner (Baseline)
The baseline selects the nearest goal point and performs performs point-based planning. In this case, the nearest point (blue) is not reachable in the environment, and results in a planning failure. Checking for reachability and collisions in the goal set is possible, but involves applying expensive heuristics prior to planning.
Qualitative Results
Below are qualitative results of successful grasps from our experiments on various objects. The grasp samples considered are shown in green. Only a portion (N=20) are shown for better visualization. A total of 100 valid grasps are considered as part of the goal set in practice. The goal set planner in these examples uses the Kernel MMD loss.
Mug
Cereal Box
Water Bottle
Bowl
Real Robot Demonstration
We execute our planner on a Franka Panda robot to demonstrate that our trajectories are transferable to a real platform. The trajectories are planned offline in Isaac Gym.
Trajectory generated in Isaac Gym.
Execution on the Franka Panda.
Trajectory generated in Isaac Gym.
Execution on the Franka Panda.
Placement
The goal set planner can handle multi-modal goal regions and adapt to changing environments where a portion of the goal region becomes unavailable. We demonstrate this behavior through a table setting task, where the robot must sequentially place mugs on a table using demonstrated goal locations.
The goal samples are sampled from three uniform distributions (green). We use the MMD terminal cost. As mugs are added, certain goal points are no longer reachable. The trajectory distribution (red lines) converges to modes which terminate in reachable portions of the table, without recomputing the goal set during execution.
Citation
@inproceedings{pavlasek2023sets,
author = {Pavlasek, Jana and Lewis, Stanley and Sundaralingam, Balakumar and Ramos, Fabio and Hermans, Tucker},
title = {Ready, Set, Plan! Planning to Goal Sets Using Generalized Bayesian Inference},
booktitle = {Conference on Robot Learning (CoRL)},
pages = {3672--3686},
volume = {229},
series = {Proceedings of Machine Learning Research},
month = {06--09 Nov},
publisher = {PMLR},
year = {2023}
}